
首先我们在学习docker之前先思考一下为什么docker会有现在如此火爆的讨论度,我认为很大一方面来自于系统复杂性的提高,docker其实是一种容器化技术,他的目的就是可以将各个模块分离开来,这也是微服务的思想,那为什么需要微服务呢,其实各位思考一下就知道,如果淘宝这个级别的应用是一个单体架构,那么要什么样的机器才可以支撑它跑起来呢? 还有人的精力是有限的,如此庞大的系统,那么谁都不能完全知道各个模块是干什么的,这对于更新迭代等都是致命的影响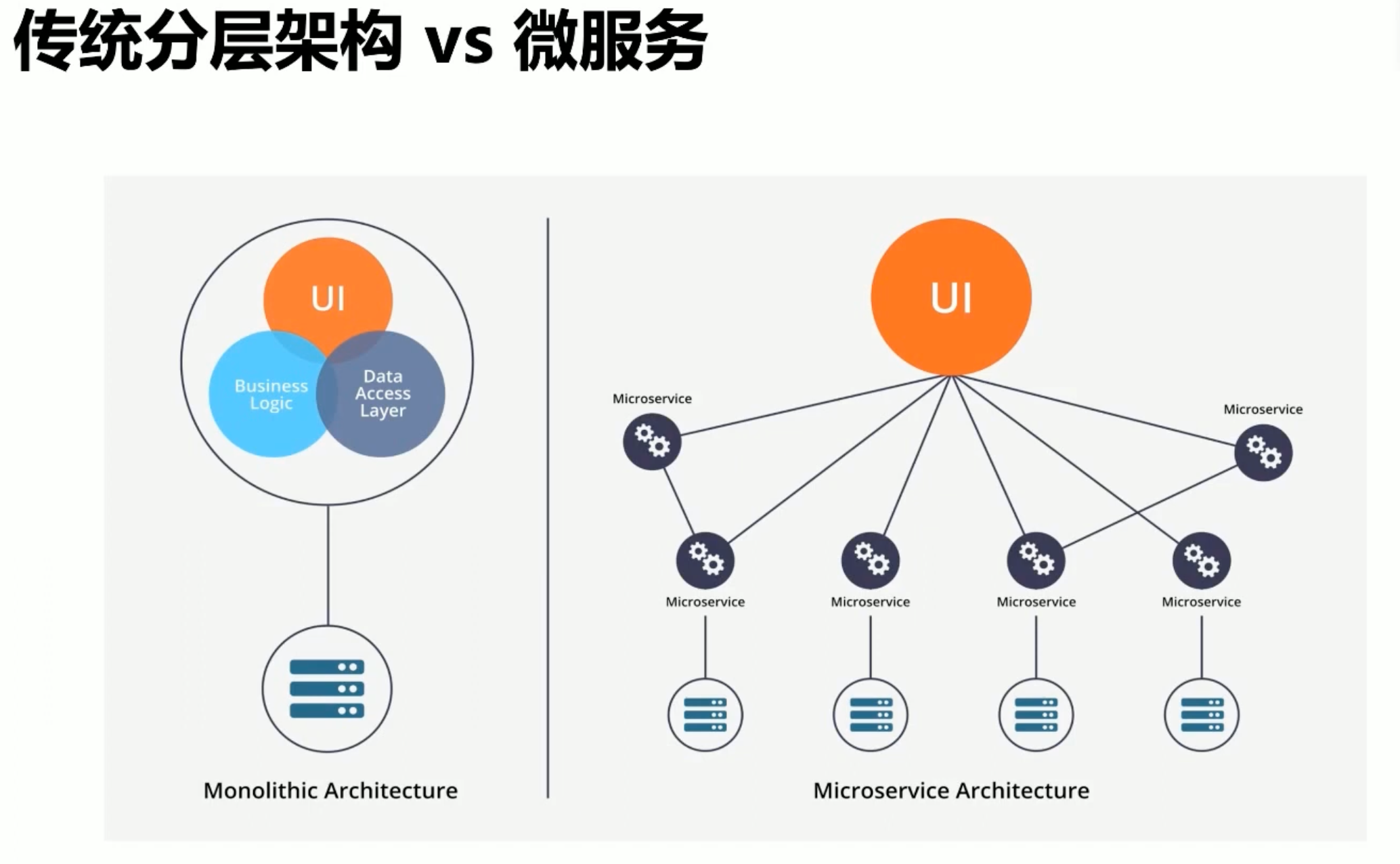
上面讲的是为什么会出现微服务化,那docker呢,这是什么,这就要更深入的研究了。我们讲一个系统拆分为各个微服务系统之后,各个服务所占用的资源其实是不多的,但是我们现在的机器性能是在逐渐上升的,如果一个服务一台机器有时就比较浪费。所以为了提升机器的资源利用率,很可能讲多个服务部署到同一台机器上,那么多个服务部署到同一个机器上会出现什么问题?
各个服务之间的隔离型不够好,比如有一个服务出现了内存泄漏,有可能导致所有的服务都挂掉,这时又有技术的进步,但不是docker,而是虚拟化技术。
上面讲道理虚拟化技术,那么docker是如何普及以及完全战胜虚拟机的呢,我们首先来看一下docker相比于虚拟机有哪些优势
- 资源利用率高,首先虚拟机你想启动起来就必须要启动一个操作系统,而一个操作系统的启动很可能就会消耗掉大量的内存,而Docker容器不包含完整的操作系统镜像,而是共享宿主机的操作系统内核,从而实现了更高效的资源利用和更快的启动速度。
- 根据namespace技术,docker可以在测试机和开发机中有相同的执行效果,而不是出现在我的机器上正常运行的情况。

上面我们大致介绍了为什么docker现在如此火爆,接下来我们就来学习一下docker
我们首先来看一下经常使用的docker命令
docker run -it 交互式运行
-d 后台运行
-p 端口映射
-v 磁盘挂在
start 启动已经终止的容器
stop 停止容器
ps 查看容器进程
pull 拉去镜像
inspect + 容器id 检查当前 docker镜像的内容
cp file <containderID>:/fileToPath
images 列取当前所有的镜像其中docker run xxx命令就是现在本地看是否可以找到xxx的镜像,如果可以就运行,否则他使用docker pull拉去镜像,然后运行。
我们看到了docker的这些内容,是不是应该有一个问题,就是我怎么使用docker来进行打包呢,可以使用dockerfile来进行操作,下面看一个例子:

docker build -t是给镜像打标签,这里我们就看到了它是如何把本地的程序打包成镜像,然后拉去的。
下面我们来看一下容器的主要特性
- 隔离型
- 安全性
- 可配额
- 便携性
docker原理
namespace
首先当我们通过 docker run -it 启动并进入一个容器之后,会发现不论是进程、网络还是文件系统,好像都被隔离了,就像这样:
[root@docker cpu]# docker run -it busybox
/ #
/ # ps
PID USER TIME COMMAND
1 root 0:00 sh
7 root 0:00 ps
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
120: eth0@if121: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ls
bin dev etc home lib lib64 proc root sys tmp usr var
lft forever / # ls bin dev etc home lib lib64 proc root sys tmp usr var - ps 命令看不到宿主机上的进程
- ip 命令也只能看到容器内部的网卡
- ls 命令看到的文件好像也和宿主机不一样
这就是 Docker 核心之一,借助 Linux Namespace 技术实现了视图隔离。
那什么是namespace技术,namespace技术是Linux Kernel提供的一种资源隔离方案:
- 系统可以为进程分配不同的namespace
- 保证不同namespace进程之间资源独立分配、进程彼此隔离,不同的Namespace之间的进程互不干扰
我们要知道namespace的目的就是对于资源进行隔离,在Linux中有以下namespace
- IPC:隔离System V IPC和POSIX消息队列。
- Network:隔离网络资源。
- Mount:隔离文件系统挂载点。
- PID:隔离进程ID。
- UTS:隔离主机名和域名。
- User:隔离用户ID和组ID。
举个例子:在不同的namespace中相同pid的进程不是同一个进程,我们在思考docker如何实现时就可以思考到:首先我们每个docker都要有一个ip+port,这就需要系统对于docker的网络进行隔离,也就是Network,然后docker中的进程有自己的pid,host上也有进程的pid,pid之间也要进行隔离,还有UTS隔离主机名和域名,这对于容器化同样是十分重要的。下面有一个概念性的描述
Namespace 是 Linux 内核用来隔离内核资源的方式。通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
Linux 提供了多个 API 用来操作 namespace,它们是 clone()、setns() 和 unshare() 函数,为了确定隔离的到底是哪项 namespace,在使用这些 API 时,通常需要指定一些调用参数:CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER、CLONE_NEWUTS 和 CLONE_NEWCGROUP。
如果想要给已存在进程设置新的namespace,可通过unshare函数(long unshare(unsigned long flags))完成设置,其入参flags表示新的namespace。当想要给已存在进程设置已存在的namespace,可通过setns函数(int setns(int fd, int nstype))来完成设置,每个进程在procfs目录下存储其相关的namespace信息,可找到已存在的namesapce,然后通过setns设置即可
无法 Namespace的资源
尽管 Linux的 Namespace机制提供了对多种系统资源的隔离,但并不是所有的系统资源都能被 Namespace隔离,以下是一些不能被 Namespace隔离的资源及其原因:
- 内核模块: 内核模块(Kernel Modules)在整个系统中是全局共享的。加载或卸载一个内核模块会影响到所有Namespace中的进程。
- 内核参数: 通过
sysctl命令设置的内核参数(如/proc/sys下的参数)是全局的,无法在不同的Namespace中进行独立设置。 - 硬件资源:硬件资源是物理存在的,无法通过软件机制进行隔离。
- CPU:尽管Cgroups可以对CPU资源进行分配和限制,但CPU本身是一个物理资源,无法在不同的Namespace中进行隔离。
- 内存:Cgroups可以对内存资源进行分配和限制,但物理内存本身无法在不同的Namespace中进行隔离。
- 磁盘:磁盘设备是物理存在的,无法在不同的Namespace中进行隔离。尽管可以通过Cgroups对磁盘I/O进行限制,但磁盘设备本身是共享的。
- 时间:系统时间(如系统时钟和硬件时钟)在整个系统中是共享的,无法在不同的Namespace中进行独立设置。
- 安全机制:一些系统级的安全机制无法在不同的Namespace中进行隔离。
- SELinux:SELinux(Security-Enhanced Linux)是一种安全模块,它的策略在整个系统中是全局的,无法在不同的Namespace中进行独立设置。
- AppArmor:类似于SELinux,AppArmor也是一种安全机制,它的配置和策略在整个系统中是全局的。
- 系统日志:系统日志(如
/var/log下的日志文件)在整个系统中是共享的,无法在不同的Namespace中进行独立管理。 - 特殊设备文件:一些特殊的设备文件(如
/dev下的某些设备文件)在不同的Namespace中是共享的,无法进行隔离。例如,/dev/null、/dev/zero等设备文件在整个系统中是全局的。
cgroup
我们使用namespace可以隔绝不同进程之间的网络,pid等,那还有什么问题呢,主机资源该怎么分配,我们如果想在一个主机上运行多个docker,不可避免的就要使用相同的cpu,memory,那如果我一个程序占用大量的memory事会影响其他容器的,不用担心,我们可以使用cgroup(control group)技术来限制,记录和隔离进程组所使用的物理资源。
Cgroups可以做什么?
Cgroups最初的目标是为资源管理提供的一个统一的框架,既整合现有的cpuset等子系统,也为未来开发新的子系统提供接口。现在的cgroups适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。Cgroups提供了一下功能:
1.限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。
2.进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。
3.记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间
4.进程组隔离(isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
5.进程组控制(control)。比如:使用freezer子系统可以将进程组挂起和恢复。
通过mount -t cgroup命令或进入/sys/fs/cgroup目录,我们看到目录中有若干个子目录,我们可以认为这些都是受 cgroups 控制的资源以及这些资源的信息。
- blkio — 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- cpu — 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- cpuacct — 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- cpuset — 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- devices — 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
- freezer — 这个子系统挂起或者恢复 cgroup 中的任务。
- memory — 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成内存资源使用报告。
- net_cls — 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- net_prio — 这个子系统用来设计网络流量的优先级
- hugetlb — 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
如何为Cgroup分配限制的资源
首先明白下,是先挂载子系统,然后才有control group的。意思就是比如想限制某些进程的资源,那么,我会先挂载memory子系统,然后在memory子系统中创建一个cgroup节点,在这个节点中,将需要控制的进程id写入,并且将控制的属性写入。
1、以memory子系统为例:
进入/sys/fs/cgroup/memory这个目录,我们创建一个test文件夹就相当于创建了一个control group了,进入test目录,你会发现test目录下自动创建了许多文件
这些文件的含义如下:

于是,限制内存使用我们就可以设置memory.limit_in_bytes
将一个进程ID加入到这个test中: echo $$ > tasks
这样就将当前这个终端进程加入到了内存限制的cgroup中了,如果需要删除cgroup只要删除刚创建的目录就可以了。
2、以CPU子系统为例:
跑一个耗费cpu的脚本
x=0
while [ True ];do
x=$x+1
done;用top命令可以看到这个脚本基本占了100%的cpu资源
下面用cgroups控制这个进程的cpu资源
mkdir -p /sys/fs/cgroup/cpu/hello/ #新建一个控制组hello
echo 50000 > /sys/fs/cgroup/cpu/hello/cpu.cfs_quota_us #将cpu.cfs_quota_us设为50000,相对于cpu.cfs_period_us的100000是50%
echo "$PID" > /sys/fs/cgroup/cpu/hello/tasks然后观察top的实时统计数据,会发现cpu占用率将近50%,看来cgroups关于cpu的控制起了效果。
Comments NOTHING