
文件系统
Union FS
在之前的docker学习中,我们重点介绍了namespace和cgroup功能,这两个功能其实都不是docker原创的,都是docker对于Linux原有的技术进行整合,那docker有没有什么创新的地方呢,就是在Union FS,这是docker所原创的。
我们在上一节提到了docker就是使用namespace和cgroup来制造一个隔离的程序运行系统,那我们怎么要让他有自己的目录呢,这就是union fs干的事,它本质上是将多个不同的目录mark成一个合并好的文件目录,然后把这个合并好的目录打包成为一个容器的文件系统,那么这个文件系统本质上就是它的一个root fs
以上只是一些基本的理解,后续如果我学到的更深层的内容会进行补充
那现在我们来看一下docker是如何根据docker来构建容器的
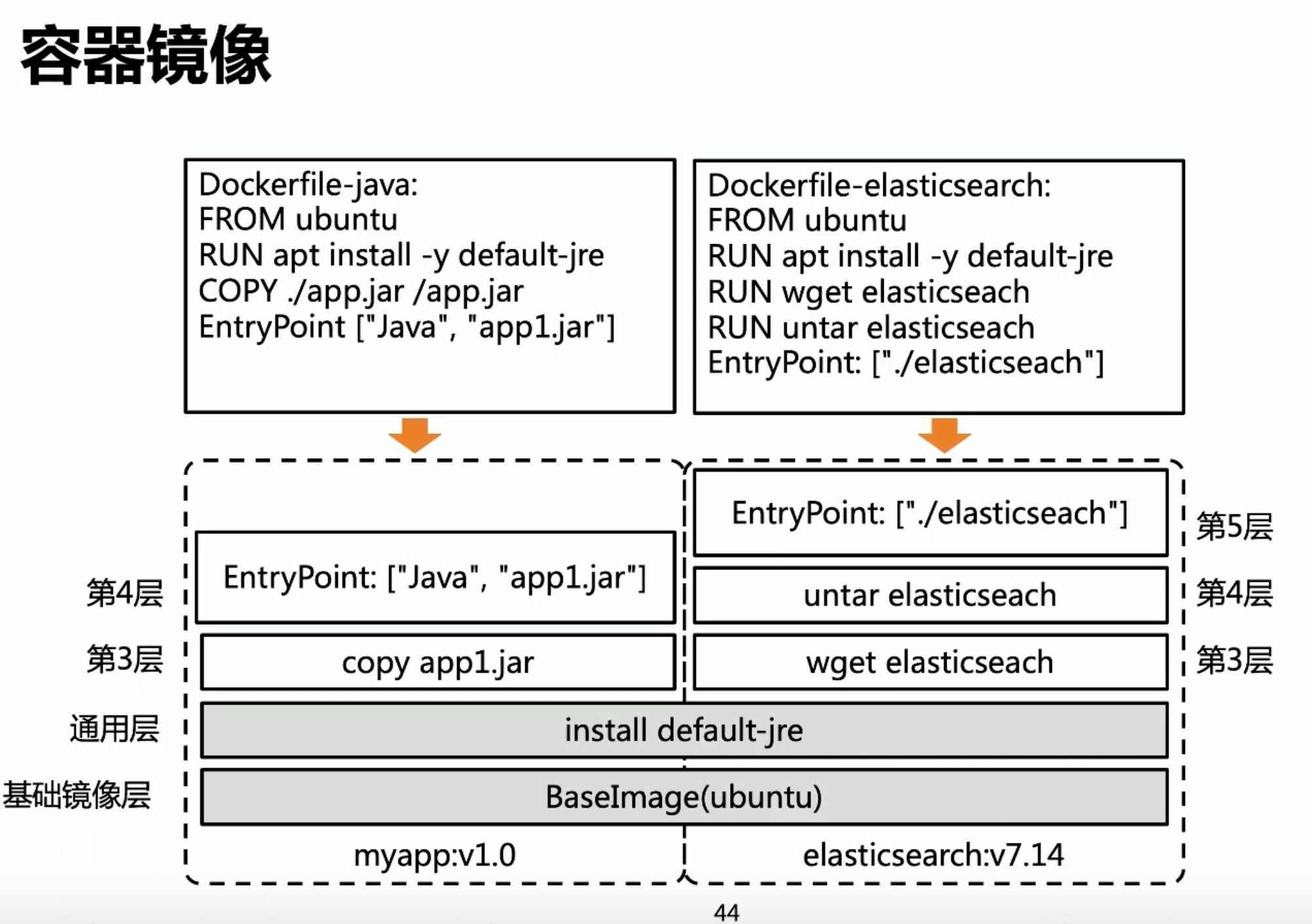
核心概念:镜像(Image) vs. 容器(Container)
首先要分清两个概念:
- 镜像(Image):一个只读的模板,里面包含了运行所需的一切:代码、运行时、库、环境变量和配置文件。它是由一系列只读的层(Layer) 构成的。你的图片里画的那些
第3层、第4层就是镜像层。 - 容器(Container):是镜像的一个可运行的实例。当你运行
docker run时,Docker会基于镜像创建一个容器,并在所有只读层之上添加一个可写的容器层(Container Layer)。
层复用(Layer Reuse)是如何工作的?
Docker使用联合文件系统(Union File System,如 AUFS, overlay2)来实现分层和复用。它的工作原理可以想象成一叠透明的幻灯片:
- 你的
Dockerfile中的每一条指令(如FROM,RUN,COPY)都会创建一个新的只读层。 - 关键点:如果两个镜像有相同的父镜像(比如都是
FROM ubuntu),并且有完全相同的指令(比如RUN apt install -y default-jre),Docker在构建第二个镜像时,就不会重新下载和安装软件包,而是直接复用之前已经创建好的、完全相同的层。
以你的图片为例:
- 你构建了第一个镜像
myapp:v1.0。
FROM ubuntu-> 下载 Ubuntu 基础层RUN apt install ...-> 安装 JRE,创建新层(我们叫它 JRE层)COPY ...和EntryPoint ...-> 为你的应用创建新的层
- 接着你构建第二个镜像
elasticsearch:v7.14。
FROM ubuntu-> 复用之前下载的 Ubuntu 基础层RUN apt install ...-> 这条指令和构建myapp时一模一样!所以Docker会直接复用之前创建好的那个 JRE层,而不是再安装一次。- 接下来的
wget,untar等指令是新的,所以Docker会为它们创建新的层。
这样做的好处巨大:
- 节省磁盘空间:
elasticsearch镜像不需要单独存储一个完整的 Ubuntu 系统和一份单独的 JRE,它只存储自己独有的层。 - 节省下载时间:如果你从仓库拉取镜像,所有可以复用的层都已经在本地了,只需要下载那些新的、独有的层。
- 加速构建过程:构建镜像时,缓存(cache)的机制就是基于层的。如果某一层没有变化,就直接使用缓存,不需要重新执行指令。
容器独立性是如何保证的?
现在我们来解决你的矛盾点:既然层是共享的,容器之间如何保持独立?
答案就在于每个容器运行时,Docker都会在镜像的所有只读层之上,添加一个薄薄的可写层(容器层)。
- 所有对容器的修改(如创建新文件、修改现有文件、删除文件)都发生在这个可写层中。
- 多个容器可以共享同一个底层镜像(只读层),但每个容器都有自己的、独立的可写层。
举个例子:
假设两个容器(Container A 和 Container B)都基于同一个 ubuntu 镜像运行。
- Container A 运行了
touch /hello.txt,创建了一个新文件。这个操作被记录在 Container A 的可写层里。 - Container B 完全看不到
/hello.txt这个文件,因为它的可写层里没有这个操作记录。它对文件系统的视图仍然是干净的原始镜像。 - 如果 Container B 尝试删除一个只读层中的系统文件(比如
/bin/ls),Docker不会真的去删除底层共享的只读文件(那样会影响到所有容器),而是在 Container B 的可写层中做一个“标记”,记录下“此文件已被删除”。于是,对于 Container B 来说,/bin/ls好像不见了,但对 Container A 和其他容器来说,这个文件依然存在。
这种技术被称为写时复制(Copy-on-Write, CoW)。
我们先来看一下典型的Linux的文件系统都有哪些

在上面其中bootfs的任务就是加载kernel,再加载完kernel之后他就会背umount了,然后rootfs会被执行。
那么docker的文件系统又是如何的呢,首先docker是没有bootfs的,因为docker的内核是依赖于主机的,但是docker有自己的rootfs,

这上面的技术就是用来保证docker所创造的各个容器都是有独立的文件系统的,不会因为使用相同的基础镜像就造成不同容器中的文件冲突问题。
在使用docker时我们可以使用overlayfs作为容器的文件系统,下面来介绍一下这个文件系统
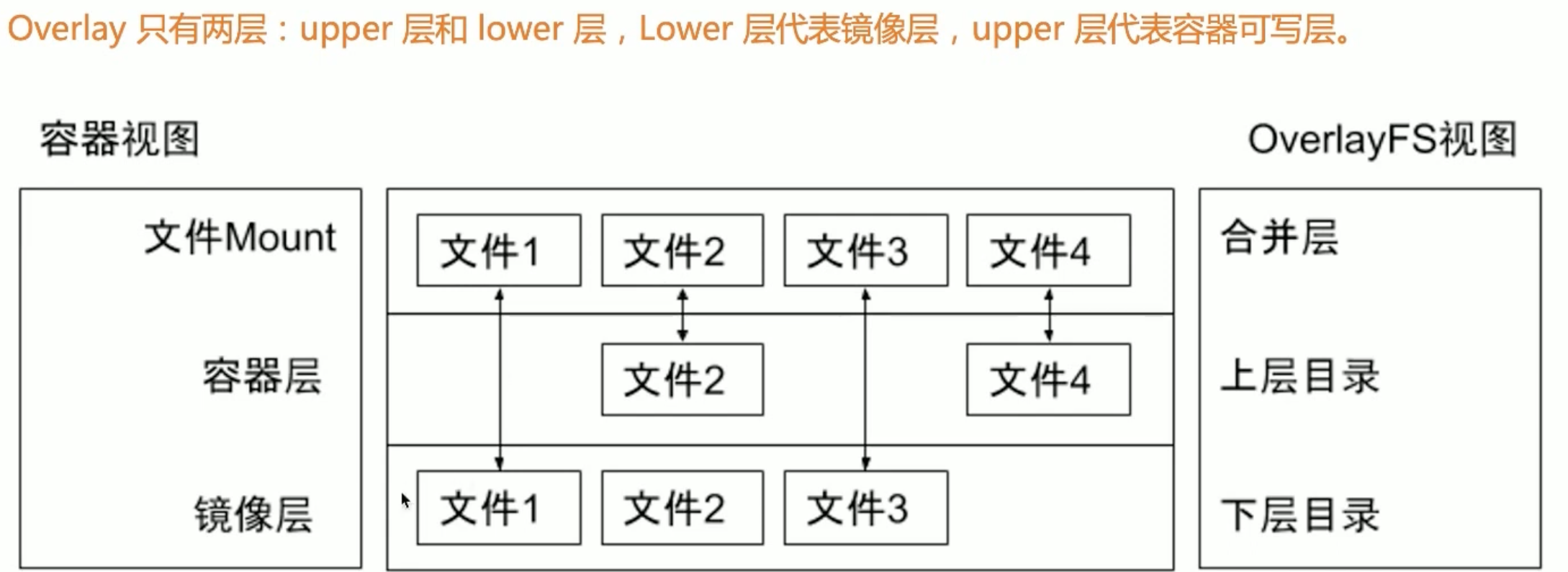
那这个怎么理解呢,就是我们的基础镜像也就是在dockerfile中的from xxx这个镜像是我们的镜像层,然后我们可能在镜像层之上又做了一些操作,这一层就是我们的容器层,然后最后我们看到的文件系统就是镜像层和文件层和并在一起的。
网络
上面我们讲了docker的文件系统,讲了不同的docker之间以及docker与host之间的文件是如何隔离的,那我们现在要看的是不同的docker之间的网络是如何隔离的,以及我们的docker之间要如何进行网络连接。
这里首先我们来复习一下,在上一章,我们讲了docker使用namespace来进行资源的隔离,这里就有网路namespace,我们在不同的namespace可以给他配置不同的网卡,防火墙等内容,这其实就实现了网络之间的隔离,然后我们现在来看一下docker网络的内容。
首先,docker有多种网络模式,我们来看一下


各位之前在使用docker构建容器的时候不是到有没有困惑,我们经常使用docker -p hport:dport做这样的映射,然后我们才可以对容器中的功能进行访问,那他到底是如何做的呢,它们之间的网络不是相互隔离的吗。

我们使用默认的方式起起docker时候会给它创建eth0网卡,并为他分发ip,然后他会和我们的主机建立网络桥设备,所以我们使用主机的时候就可以通过docker的ip+port来进行访问,但是外部的人不知道啊,所以我们可以吧docker的端口映射到主机的端口,这样我们在访问主机的端口的时候就会自动的去访问docker的端口
docker build过程

这里有一个比较重要的点就是docker build时会吧当前文件夹作为构建的上下文传递给docker daemon的,所以如果你在一个很大的文件下执行docker build,即使要构建的容器镜像很小也很可能会执行比较长的时间。
然后可以像gitignore一样在dockerignore中告诉docker要忽略哪些文件。
然后我们通过一个例子来查看docker构建镜像的过程,我们在上面看到了docker使用镜像层将文件系统进行隔离,使得我们在复用镜像的时候不会影响到基础镜像,那现在我们来看一下如何通过dockerfile来构建一个镜像

我们看到首先它会将build所在的上下文发送给docker daemon,然后这里每一个指令其实都是一个镜像层, 他会为每一个层计算一个校验和,如果这个校验和与之前的一致的话,他就会认为当前层与之前是一致的,然后他就会使用原来的缓存。

那我们在指导dockerfile构建的原理之后是不是可以找到一个技巧,我最不易发生改变的,最稳定的层是不是应该构建在dockerfile的最顶层,这样可以帮助我们更快的使用缓存构建镜像。


这里有一个比较重要的点是如果add的src是一个本地压缩文件,那么在拷贝到目标的时候会进行解压缩操作。


这里解释一下entrypoint有什么作用以及他和cmd,run的区别
RUN (构建时执行)
- 执行时机:在构建镜像(
docker build) 期间执行。 - 作用:用于在镜像中添加新的层。通常用于安装软件包、编译代码、创建文件和目录等,目的是为了准备镜像的运行环境。
- 例子:在你的指令中: dockerfile
- ```
RUN apt-get update \
&& apt-get install -y curl \
&& rm -rf /var/lib/apt/lists/*
这会在构建镜像时发生:
1. 更新软件包列表。
2. 安装 `curl` 工具。
3. 清理缓存以减小镜像体积。
这些操作的结果(一个包含了 `curl` 的系统层)会被永久地固化到你的镜像中。
##### 2. CMD (运行时执行)
- **执行时机**:在**启动容器(`docker run`)** 时执行。
- **作用**:为正在运行的容器提供**默认的执行命令**。一个 Dockerfile 中只能有一条 `CMD` 指令,如果有多条,则只有最后一条生效。
- **关键特性**:`CMD` 定义的命令非常容易被覆盖。当用户在 `docker run` 命令的末尾指定了其他命令时,`CMD` 的内容会被完全忽略。
- **例子**:
dockerfile
- ```
CMD [ "curl", "-s", "http://myip.ipip.net" ]这表示:当有人简单地通过 docker run your-image-name 启动容器时,容器默认会执行 curl -s http://myip.ipip.net 这个命令来查询公网IP,执行完后容器进程就退出了(因为 curl 命令运行结束了)。
你例子中的问题:
如果你基于这个 Dockerfile 构建镜像并运行,你会发现容器在输出 IP 信息后立即就退出了。这通常是设计意图(这是一个只运行一次的任务容器)。但如果你想让容器保持运行,你需要一个长期运行的进程,比如 CMD ["nginx", "-g", "daemon off;"]。
3. ENTRYPOINT (也是运行时执行)
ENTRYPOINT 和 CMD 一样,也是在容器启动时执行,但它们的关系非常微妙且重要。
- 执行时机:同样在启动容器(
docker run) 时执行。 - 作用:配置容器作为一个可执行程序来运行。它比
CMD更“固执”,不容易被覆盖。 - 与
CMD的交互:
- 如果
ENTRYPOINT存在:CMD的内容不再直接作为命令执行,而是会变成ENTRYPOINT的参数。 - 覆盖方式不同:使用
docker run时,--entrypoint参数可以覆盖ENTRYPOINT,而直接在run后面添加的参数会覆盖CMD。
组合使用的最佳实践:
这是一种非常常见的模式,让你既有一个固定的主程序,又可以有灵活的参数。
举例说明:
假设我们有这样一个 Dockerfile:
dockerfile
FROM ubuntu
RUN apt-get update && apt-get install -y curl
ENTRYPOINT ["curl"]
CMD ["-s", "http://myip.ipip.net"]- 场景一:直接运行
docker run my-curl-image ENTRYPOINT是curlCMD是-s http://myip.ipip.net- 最终执行的命令是:
curl -s http://myip.ipip.net - 结果:安静地(
-s)输出 IP 信息。 - 场景二:运行时提供参数
docker run my-curl-image -i ENTRYPOINT依然是curl- 你提供的
-i参数覆盖了整个CMD - 最终执行的命令是:
curl -i - 结果:
-i参数会让curl输出响应头信息,但因为没有URL,会报错。这其实不好。 - 场景三(更常见的用法):把URL作为参数
docker run my-curl-image -s http://www.google.com ENTRYPOINT是curl- 你提供的
-s http://www.google.com覆盖了CMD - 最终执行的命令是:
curl -s http://www.google.com - 结果:curl 会去访问 Google 的首页。这样,你的镜像就像一个定制的
curl工具,非常灵活!

当你执行一条命令 docker run nginx 时,发生了什么?
- Docker CLI:你键入
docker run nginx。 - Docker Daemon (dockerd):Docker守护进程接收到这个指令。
- containerd:
dockerd通过gRPC API调用containerd,告诉它:“请准备并运行一个nginx容器”。 - containerd:
containerd会检查本地是否有nginx镜像,如果没有,会从仓库拉取。然后它准备容器的运行时规范(OCI spec)。 - containerd-shim:
containerd会启动一个轻量的助手进程叫containerd-shim。这个shim的作用很重要:
- 它作为容器进程的父进程,允许
containerd在不影响容器运行的情况下重启或升级。 - 它将容器的标准输入输出(stdio)转发给Docker,这样你才能看到日志。
- 它保证容器进程不会因为父进程退出而变成孤儿进程。
- runc:
containerd-shim最终调用runc工具。 - runc:
runc根据镜像和配置,利用Linux内核的命名空间(Namespace)和控制组(Cgroup)等技术,真正地创建并启动容器进程。
整个调用链可以简化为:docker -> dockerd -> containerd -> containerd-shim -> runc -> container process
Comments NOTHING