
由于我们在项目中经常会用到定时器的内容,比如每20分钟计算一下当前项目中最热门的一些文章,又或者定时清理过期的key等等,这些功能都需要定时器来帮助我们实现,我这里就想实现一个分布式定时器,思路参考小徐先生的公众号。
核心功能
首先定时器的核心功能就是在我们设置的时间触发任务,那么我们怎么知道当前时间是否有任务要触发呢?
使用最简单粗暴的方法 -- 轮询
- 首先用户注册定时器到系统中,并表明要触发的时间
- 系统每隔一个微小的时间进行轮询,党有小于当前时间的任务,将其移出并执行
优化
这样一个简单的乞丐级定时器就设置完成了,那么这里有什么问题吗,首先性能太低,我们如果不使用任何数据结构,仅仅使用队列来存储定时器的数据的话,每次轮询都要历遍队列,时间复杂度太高,那么我们的优化点就在存储结构,这里sptimer中选择redis中的ZSet作为定时起的存储结构,使用score来存储定时器执行的时间戳。
- 每次添加定时任务时,执行 ZAdd 动作,以执行时间的时间戳作为排序的键(Score) 进行有序结构的搭建;
- 每次查询定时任务时,执行 ZRangeByScore 动作,以当前时刻的时间戳加上一个微小偏移量作 score 的左右边界.
存储结构优化
纵向分治
优化完存储的底层数据结构之后,我们还可以优化一下系统的存储结构,在上面所述的,我们是在一个key中存储所有的score,那么如果我只是想得到某一瞬间需要执行的时间,那么剩下的所有的时间都是多余的,所以这里就有一个很常见的优化策略,分片优化。就是在存储定时任务之前,我们计算出要插入的时间所属的片,这里以一分钟为一片
- 插入每笔定时任务时,根据执行时间推算出所属的分钟级时间范围表达式,例如:2022-09-17-11:00:03 -> 2022-09-17-11:00:00_2022-09-17-11:01:00
- 以分钟级时间范围表达式为 key,将定时任务任务插入到不同 ZSet 中,组成一系列相互隔离的有序表结构.
- 每一次查询过程中,同样根据当前时刻推算出对应分钟级时间范围表达式,并以此为 key 查找到对应的有序表进行 ZRange 查询.
横向分治
纵向分治中我们根据时间线将其划分为一个个的时间片,那么横向分治就是划分时间片为一个个的桶,目的如下
- 首先对于单核机器来说,这么设计可以提高单核的并法度
- 对于分布式集群来说,在同一时间有可能会有多个机器去访问,那么使用桶划分的做法就可以让更多的机器进行工作,提高并发度。
我们可以在配置文件中设置每一个时间片中通的最大数量,这里使用分布式锁控制并发
服务框架
上面我们对于如何存储定时器时间以及如何触发事件进行了总结,那下面我们就来看一下当前系统是如何设计工作的。
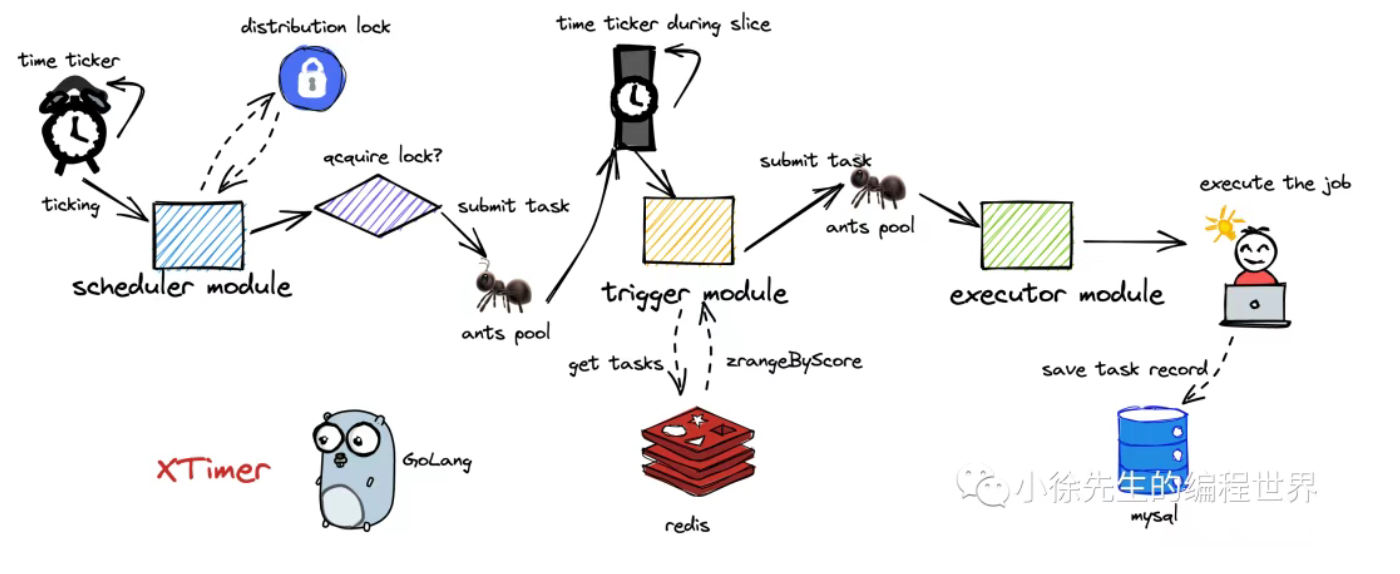
我们首先来看一下总体的服务框架,这个系统包含有调度器模块(scheduler),触发器模块(trigger)和执行器模块(executor),我们分别来介绍一下各个模块的功能。
这里我先声明,各个模块都是由独立的协程负责的,在程序开始运行的时候,各个模块作为后台协程会一直工作保证系统的正常运行。
调度器模块
首先我们来看调度器模块,他的目的是每隔一定时间,讲二维分片中的每个桶负责给对应的执行器模块,保证每个桶既不会泄漏,也不会被重复执行。
流程如下:
- 基于 time ticker 每隔 1s 进行主动轮询,基于当前时刻推算出对应的分钟级时间范围表达式;
- 读取配置获得最大桶数的信息,基于时间范围拼接桶号,获得当前需要关心的一系列二维分片的 key;
- 尝试抢占对应于每一个二维分片的分布式锁,并将锁的过期时间设置为一个小于分片时间范围的值;
- 抢锁成功,则从协程池中取出一个协程调度一个触发器进行作业;
不知道各位看到这里是否还是有些疑惑,这到底在干什么,这里我结合实际实现给各位看一下这个系统的两个表
CREATE TABLE IF NOT EXISTS `task`
(
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`app` varchar(255) NOT NULL COMMENT '应用名',
`timer_id` bigint(20) NOT NULL COMMENT '定时器ID',
`output` varchar(256) DEFAULT NULL COMMENT '执行结果',
`run_timer` datetime NOT NULL COMMENT '执行时间',
`cost_time` int(8) DEFAULT NULL COMMENT '执行耗时',
`status` int(4) NOT NULL COMMENT '当前状态',
`created_at` datetime NOT NULL COMMENT '创建时间',
`updated_at` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`deleted_at` datetime DEFAULT NULL COMMENT '删除时间',
PRIMARY KEY (`id`) USING BTREE COMMENT '主键索引',
UNIQUE KEY `idx_def_timer` (`timer_id`,`run_timer`) USING BTREE COMMENT '定时器执行时间索引',
KEY `idx_run_timer` (`run_timer`) COMMENT '执行时间索引'
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
CREATE TABLE IF NOT EXISTS `timer`
(
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`app` varchar(255) NOT NULL COMMENT '应用名',
`name` varchar(255) NOT NULL COMMENT '定时器name',
`status` smallint(255) NOT NULL COMMENT '定时器状态 1未激活 2激活',
`cron` varchar(255) NOT NULL COMMENT '定时表达式',
`notify_http_param` json DEFAULT NULL COMMENT 'http 参数',
`deleted_at` datetime DEFAULT NULL COMMENT '删除时间',
`created_at` datetime NOT NULL COMMENT '创建时间',
`updated_at` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uni_app` (`app`,`name`) USING BTREE COMMENT 'app name 索引'
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;其中timer的notify_http_param定义如下
type NotifyHTTPParam struct {
Method string `json:"method,omitempty" binding:"required"` // POST,GET 方法
URL string `json:"url,omitempty" binding:"required"` // URL 路径
Header map[string]string `json:"header,omitempty"` // header 请求头
Body string `json:"body,omitempty"` // 请求参数体
}这里存储的就是method,也就是当定时器被触发是执行的方法,这些就是我们创建定时器时持久化存储的内容,但这些好像和我们上面讲的不一样啊,我们不是说使用redis的zset来进行分配存储吗,这里我们后台还会有一个模块migator,后面会讲,它有两个作用,一个是定时将task从mysql中迁移到redis,另一个是批量生产task,比如一个定时器是10分钟执行一次,那么migator根据我们设置的step来生产task,比如我们设置的step时1小时,那么migator针对10分钟执行一次的定时器就会生产6个task,执行时间就是它所需要执行的时间
在看完存储结构之后我们现在应该理解了:我们的redis中存储的就是key为定时任务时间戳_桶号,value为时间戳的任务,那调度器的任务是什么呢,就是在定时任务被触发之前,将它分发给各个触发器,我们可以看到每隔1s执行一次,然后抢夺分布式锁,这里有问题啊如果我执行成功了那下一秒怎么办呢,不用急,如果我们抢夺成功分布式锁并讲其发送给对应的触发器,那么我们会延长分布式锁的时间,保证同一个桶只会被一个协程拥有。下面看一下代码
func (w *Worker) Start(ctx context.Context) error {
w.trigger.Start(ctx)
//配置文件中的时间间隔为1s
ticker := time.NewTicker(time.Duration(w.appConfProvider.Get().TryLockGapMilliSeconds) * time.Millisecond)
defer ticker.Stop()
for range ticker.C {
select {
case <-ctx.Done():
log.WarnContext(ctx, "stopped")
return nil
default:
}
//根据配置文件可知
//这里每隔一秒对分片中的资源进行重新分配
//保证每隔分片的所有桶都有对应的trigger执行
w.handleSlices(ctx)
}
return nil
}
func (w *Worker) handleSlices(ctx context.Context) {
for i := 0; i < w.getValidBucket(ctx); i++ {
w.handleSlice(ctx, i)
}
}
// 禁用动态分桶能力
func (w *Worker) getValidBucket(ctx context.Context) int {
return w.appConfProvider.Get().BucketsNum
}
func (w *Worker) handleSlice(ctx context.Context, bucketID int) {
// log.InfoContextf(ctx, "scheduler_1 start: %v", time.Now())
now := time.Now()
//这里是一种容错和兜底机制,因为可能由于网络延迟等分布式系统中各个节点的时间不一定一致,
//所以使用这种方法可以在一定程度上重试上一分钟没有被执行的任务。如果上一分钟执行成功了也不用担心
//一方面我们的分布式锁如果执行成功会设置过期时间为130s,所以上一分钟的依然持有锁,并且我们会比对当前时间和上一分钟的时间
//保证不重复执行任务
if err := w.pool.Submit(func() {
w.asyncHandleSlice(ctx, now.Add(-time.Minute), bucketID)
}); err != nil {
log.ErrorContextf(ctx, "[handle slice] submit task failed, err: %v", err)
}
if err := w.pool.Submit(func() {
w.asyncHandleSlice(ctx, now, bucketID)
}); err != nil {
log.ErrorContextf(ctx, "[handle slice] submit task failed, err: %v", err)
}
// log.InfoContextf(ctx, "scheduler_1 end: %v", time.Now())
}
func (w *Worker) asyncHandleSlice(ctx context.Context, t time.Time, bucketID int) {
// log.InfoContextf(ctx, "scheduler_2 start: %v", time.Now())
// defer func() {
// log.InfoContextf(ctx, "scheduler_2 end: %v", time.Now())
// }()
locker := w.lockService.GetDistributionLock(utils.GetTimeBucketLockKey(t, bucketID))
if err := locker.Lock(ctx, int64(w.appConfProvider.Get().TryLockSeconds)); err != nil {
// log.WarnContextf(ctx, "get lock failed, err: %v, key: %s", err, utils.GetTimeBucketLockKey(t, bucketID))
return
}
log.InfoContextf(ctx, "get scheduler lock success, key: %s", utils.GetTimeBucketLockKey(t, bucketID))
ack := func() {
//延长持锁时间
if err := locker.ExpireLock(ctx, int64(w.appConfProvider.Get().SuccessExpireSeconds)); err != nil {
log.ErrorContextf(ctx, "expire lock failed, lock key: %s, err: %v", utils.GetTimeBucketLockKey(t, bucketID), err)
}
}
if err := w.trigger.Work(ctx, utils.GetSliceMsgKey(t, bucketID), ack); err != nil {
log.ErrorContextf(ctx, "trigger work failed, err: %v", err)
}
}w.trigger.Work(ctx, utils.GetSliceMsgKey(t, bucketID), ack);这个方法我们可以看到,当scheduler拿到一个桶之后,它会让每个桶被trigger所持有并执行。下面我们来介绍tirgger
trigger
trigger时scheduler和executor的中间层,上接scheduler拿到桶,下接executor将桶中的所有任务分发给对应的执行器,让执行器执行任务,我们可以看到的是,这个系统有一个设计非常巧妙的地方,就是它不同系统之间不是通过消息队列来进行联系的,而是通过ants协程库来进行联系的,所以这个分布式定时器又叫基于协程池架构的分布式定时器。
那么我们来看一下trigger是如何工作的。
触发器按照我们上面的思路,在找到对应的桶之后会取出桶中的左右数据,然后判断这个定时器是否可以执行,如果可以执行,他会在ants中启动executor模块去执行任务,触发器在将任务分发给执行器模块之后会讲分布式锁的过期时间更新为更长的时间,也就是我们在调度器模块中看到的ack函数
func (w *Worker) Work(ctx context.Context, minuteBucketKey string, ack func()) error {
// log.InfoContextf(ctx, "trigger_1 start: %v", time.Now())
// defer func() {
// log.InfoContextf(ctx, "trigger_1 end: %v", time.Now())
// }()
// 进行为时一分钟的 zrange 处理
startTime, err := getStartMinute(minuteBucketKey)
if err != nil {
return err
}
conf := w.confProvider.Get()
ticker := time.NewTicker(time.Duration(conf.ZRangeGapSeconds) * time.Second)
defer ticker.Stop()
endTime := startTime.Add(time.Minute)
//notifier相当于错误通告管道,目的就是在处理过程中如果出现错误就处理,而不是在处理完才处理
notifier := concurrency.NewSafeChan(int(time.Minute/(time.Duration(conf.ZRangeGapSeconds)*time.Second)) + 1)
defer notifier.Close()
var wg sync.WaitGroup
wg.Add(1)
go func() {
// log.InfoContextf(ctx, "trigger_2 start: %v", time.Now())
// defer func() {
// log.InfoContextf(ctx, "trigger_2 end: %v", time.Now())
// }()
defer wg.Done()
if err := w.handleBatch(ctx, minuteBucketKey, startTime, startTime.Add(time.Duration(conf.ZRangeGapSeconds)*time.Second)); err != nil {
notifier.Put(err)
}
}()
for range ticker.C {
select {
case e := <-notifier.GetChan():
err, _ = e.(error)
return err
default:
}
if startTime = startTime.Add(time.Duration(conf.ZRangeGapSeconds) * time.Second); startTime.Equal(endTime) || startTime.After(endTime) {
break
}
// log.InfoContextf(ctx, "start time: %v", startTime)
wg.Add(1)
go func(startTime time.Time) {
// log.InfoContextf(ctx, "trigger_2 start: %v", time.Now())
// defer func() {
// log.InfoContextf(ctx, "trigger_2 end: %v", time.Now())
// }()
defer wg.Done()
if err := w.handleBatch(ctx, minuteBucketKey, startTime, startTime.Add(time.Duration(conf.ZRangeGapSeconds)*time.Second)); err != nil {
notifier.Put(err)
}
}(startTime)
}
wg.Wait()
select {
case e := <-notifier.GetChan():
err, _ = e.(error)
return err
default:
}
ack()
log.InfoContextf(ctx, "ack success, key: %s", minuteBucketKey)
return nil
}
func (w *Worker) handleBatch(ctx context.Context, key string, start, end time.Time) error {
bucket, err := getBucket(key)
if err != nil {
return err
}
tasks, err := w.task.GetTasksByTime(ctx, key, bucket, start, end)
if err != nil {
return err
}
timerIDs := make([]uint, 0, len(tasks))
for _, task := range tasks {
timerIDs = append(timerIDs, task.TimerID)
}
// log.InfoContextf(ctx, "key: %s, get tasks: %+v, start: %v, end: %v", key, timerIDs, start, end)
for _, task := range tasks {
task := task
if err := w.pool.Submit(func() {
// log.InfoContextf(ctx, "trigger_3 start: %v", time.Now())
// defer func() {
// log.InfoContextf(ctx, "trigger_3 end: %v", time.Now())
// }()
if err := w.executor.Work(ctx, utils2.UnionTimerIDUnix(task.TimerID, task.RunTimer.UnixMilli())); err != nil {
log.ErrorContextf(ctx, "executor work failed, err: %v", err)
}
}); err != nil {
return err
}
}
return nil
}其实从上面来看过程也不算复杂,就是每秒钟从redis中读取数据,然后将其讲稿exectuor执行。
那下面就该讲exectuor了,这个更没什么可讲的,就是从数据库中拿到task,然后执行task
executor
直接看代码吧
func (w *Worker) Work(ctx context.Context, timerIDUnixKey string) error {
// log.InfoContextf(ctx, "executor_1 start: %v", time.Now())
// defer func() {
// log.InfoContextf(ctx, "executor_1 end: %v", time.Now())
// }()
// 拿到消息,查询一次完整的 timer 定义
timerID, unix, err := utils2.SplitTimerIDUnix(timerIDUnixKey)
if err != nil {
return err
}
if exist, err := w.bloomFilter.Exist(ctx, utils2.GetTaskBloomFilterKey(utils2.GetDayStr(time.UnixMilli(unix))), timerIDUnixKey); err != nil || exist {
log.WarnContextf(ctx, "bloom filter check failed, start to check db, bloom key: %s, timerIDUnixKey: %s, err: %v, exist: %t", utils2.GetTaskBloomFilterKey(utils2.GetDayStr(time.UnixMilli(unix))), timerIDUnixKey, err, exist)
// 查库判断定时器状态
task, err := w.taskDAO.GetTask(ctx, taskdao.WithTimerID(timerID), taskdao.WithRunTimer(time.UnixMilli(unix)))
if err == nil && task.Status != consts.NotRunned.ToInt() {
// 重复执行的任务
log.WarnContextf(ctx, "task is already executed, timerID: %d, exec_time: %v", timerID, task.RunTimer)
return nil
}
}
return w.executeAndPostProcess(ctx, timerID, unix)
}
func (w *Worker) executeAndPostProcess(ctx context.Context, timerID uint, unix int64) error {
// 未执行,则查询 timer 完整的定义,执行回调
timer, err := w.timerService.GetTimer(ctx, timerID)
if err != nil {
return fmt.Errorf("get timer failed, id: %d, err: %w", timerID, err)
}
// 定时器已经处于去激活态,则无需处理任务
if timer.Status != consts.Enabled {
log.WarnContextf(ctx, "timer has alread been unabled, timerID: %d", timerID)
return nil
}
execTime := time.Now()
resp, err := w.execute(ctx, timer)
// log.InfoContextf(ctx, "execute timer: %d, resp: %v, err: %v", timerID, resp, err)
return w.postProcess(ctx, resp, err, timer.App, timerID, unix, execTime)
}
func (w *Worker) execute(ctx context.Context, timer *vo.Timer) (map[string]interface{}, error) {
var (
resp map[string]interface{}
err error
)
switch strings.ToUpper(timer.NotifyHTTPParam.Method) {
case nethttp.MethodGet:
err = w.httpClient.Get(ctx, timer.NotifyHTTPParam.URL, timer.NotifyHTTPParam.Header, nil, &resp)
case nethttp.MethodPatch:
err = w.httpClient.Patch(ctx, timer.NotifyHTTPParam.URL, timer.NotifyHTTPParam.Header, timer.NotifyHTTPParam.Body, &resp)
case nethttp.MethodDelete:
err = w.httpClient.Delete(ctx, timer.NotifyHTTPParam.URL, timer.NotifyHTTPParam.Header, timer.NotifyHTTPParam.Body, &resp)
case nethttp.MethodPost:
err = w.httpClient.Post(ctx, timer.NotifyHTTPParam.URL, timer.NotifyHTTPParam.Header, timer.NotifyHTTPParam.Body, &resp)
default:
err = fmt.Errorf("invalid http method: %s, timer: %s", timer.NotifyHTTPParam.Method, timer.Name)
}
return resp, err
}
func (w *Worker) postProcess(ctx context.Context, resp map[string]interface{}, execErr error, app string, timerID uint, unix int64, execTime time.Time) error {
go w.reportMonitorData(app, unix, execTime)
if err := w.bloomFilter.Set(ctx, utils2.GetTaskBloomFilterKey(utils2.GetDayStr(time.UnixMilli(unix))), utils2.UnionTimerIDUnix(timerID, unix), consts.BloomFilterKeyExpireSeconds); err != nil {
log.ErrorContextf(ctx, "set bloom filter failed, key: %s, err: %v", utils2.GetTaskBloomFilterKey(utils2.GetDayStr(time.UnixMilli(unix))), err)
}
task, err := w.taskDAO.GetTask(ctx, taskdao.WithTimerID(timerID), taskdao.WithRunTimer(time.UnixMilli(unix)))
if err != nil {
return fmt.Errorf("get task failed, timerID: %d, runTimer: %d, err: %w", timerID, time.UnixMilli(unix), err)
}
respBody, _ := json.Marshal(resp)
task.Output = string(respBody)
if execErr != nil {
task.Status = consts.Failed.ToInt()
} else {
task.Status = consts.Successed.ToInt()
}
return w.taskDAO.UpdateTask(ctx, task)
}
Comments NOTHING